파이썬 데이터 분석 실무 테크닉 100
02장 _ 대리점 데이터를 가공하는 테크닉 [ 데이터 가공 ]
1. 데이터 불러오기
import pandas as pd
uriage_data = pd.read_csv("C:/data/uriage.csv")
uriage_data.head()
kokyaku_data = pd.read_excel("C:/data/kokyaku_daicho.xlsx")
kokyaku_data.head()

item_name 에는 오류, item_price에는 결측치가 존재하는 것을 확인할 수 있다.
2. 데이터의 오류 살펴보기
uriage_data["item_name"]
item_name에 공백이 포함되거나 대문자, 소문자가 섞여있는 오류를 확인할 수 있다.
uriage_data["item_price"]
item_price에서는 결측치가 존재하는 것을 확인할 수 있다.
3. 데이터에 오류가 있는 상태로 집계 해보기
데이터의 오류가 집계에 어떤 영향을 미치는지 확인해보자
1. 상품별 월 매출 합계 집계
# 날짜를 연월 형태로 바꾸기
uriage_data["purchase_date"] = pd.to_datetime(uriage_data["purchase_date"])
uriage_data["purchase_month"] = uriage_data["purchase_date"].dt.strftime("%Y%m")
# size, count = 개수
result = uriage_data.pivot_table(index="purchase_month", columns="item_name",
aggfunc="size", fill_value=0)
result
'상품S'와 '상품s'는 같은 상품임에도 다른 상품으로 집계되었다.
2. values = "item_price"로 설정해서 집계
result = uriage_data.pivot_table(index="purchase_month", columns="item_name",
values="item_price", aggfunc="sum", fill_value=0)
result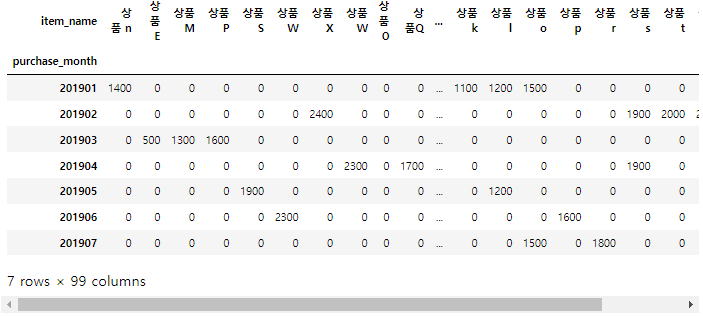
1번과 마찬가지로 이번에도 집계 결과가 올바르지 않은 것을 확인할 수 있다.
- 데이터에 오류가 있는 상태로 집계, 분석하면 의미 없는 결과가 나오므로 데이터 가공은 아주 중요하다
4. 상품명 오류 수정하기
# 상품명의 unique 수 확인
len(uriage_data["item_name"].unique()) # 99uriage_data["item_name"] = uriage_data["item_name"].str.upper()
uriage_data["item_name"] = uriage_data["item_name"].str.replace(" ", "")
uriage_data["item_name"]
uriage_data["item_name"].unique()
len(uriage_data["item_name"].unique()) # 26
상품명의 개수가 A~Z까지 26개로 잘 수정된 것을 확인할 수 있다.
5. 금액의 결측치 수정하기
# 결측치 확인
uriage_data.isnull().any(axis=0)
uriage_data.isnull().sum()

pri_is_null = uriage_data["item_price"].isnull()
for name in list(uriage_data.loc[pri_is_null, "item_name"].unique()):
price = uriage_data.loc[(~pri_is_null) & (uriage_data["item_name"] == name), "item_price"].max()
uriage_data["item_price"].loc[(pri_is_null) & (uriage_data["item_name"] == name)] = price
uriage_data.head()
결측치가 없으면서 상품명이 같은 제품의 price를 가져와 결측치를 수정해주었다.
결측치의 개수를 확인해보면
uriage_data.isnull().sum()
결측치가 잘 수정된 것을 확인할 수 있다.
# 금액이 정상적으로 수정됐는지 확인
for name in list(uriage_data["item_name"].sort_values().unique()):
print(name, "의 최고가 : ", str(uriage_data.loc[uriage_data["item_name"]==name]["item_price"].max())
,"의 최저가 : ", str(uriage_data.loc[uriage_data["item_name"]==name]["item_price"].min(skipna=False)))
최고가와 최저가가 일치하는 것으로 보아 결측치가 잘 수정된 것을 확인할 수 있다.
- skipna는 NaN의 무시 여부를 설정한다.
6. 고객 이름 오류 수정하기
# 고객 이름 확인
kokyaku_data["고객이름"].head()
uriage_data["customer_name"].head()# 공백 제거하기
kokyaku_data["고객이름"] = kokyaku_data["고객이름"].str.replace(" ", "")
kokyaku_data["고객이름"].head()

7. 날짜 오류 수정하기
kokyaku_data["등록일"].head()
date_is_str = kokyaku_data["등록일"].astype("str").str.isdigit()
date_is_str.sum() # 22
엑셀 날짜형 데이터가 숫자로 잘못 읽혀왔으므로 timedelta()를 이용해 수정해주자
# 숫자를 날짜로 변경
date_cha = pd.to_timedelta(kokyaku_data.loc[date_is_str, "등록일"].astype("float"), unit="D") + pd.to_datetime("1900/01/01")
date_cha
# 서식 통일
date_not_str = pd.to_datetime(kokyaku_data.loc[~date_is_str, "등록일"])
date_not_str
# 결합해 "등록일"로 다시 저장
kokyaku_data["등록일"] = pd.concat([date_cha, date_not_str])
kokyaku_data
kokyaku_data["등록연월"] = kokyaku_data["등록일"].dt.strftime("%Y%m")
gr = kokyaku_data.groupby("등록연월").count()["고객이름"]
gr
# 등록일 칼럼에 숫자 데이터가 남아있는지 확인
date_is_str = kokyaku_data["등록일"].astype("str").str.isdigit()
date_is_str.sum() # 0숫자 데이터가 22개에서 0개로 잘 수정된 것이 확인된다.
8. 고객 이름을 키로 두 데이터 결합(join)하기
uriage_data의 "customer_name"과 kokyaku_data의 "고객이름"을 키로 지정해 결합해보자
join_data = pd.merge(uriage_data, kokyaku_data,
left_on = "customer_name", right_on = "고객이름", how = "left")
join_data = join_data.drop("customer_name", axis=1)
join_data
9. 정제한 데이터 출력(덤프) 하기
컬럼의 순서에서 purchase_date, purchase_month는 가까이 있는 것이 좋으니 수정해보자
dump_data = join_data[["purchase_date", "purchase_month", "item_name", "item_price", "고객이름", "지역", "등록일"]]
dump_data
# 출력하기
dump_data.to_csv("c:/data/dump_data.csv", index=False)
10. 데이터 집계하기
import_data = pd.read_csv("c:/data/dump_data.csv")
import_data# 월별, 상품별 집계
byItem = import_data.pivot_table(index="purchase_month", columns="item_name",
aggfunc="size", fill_value=0)
byItem
# 월별, 상품별 매출 금액 집계
byPrice = import_data.pivot_table(index="purchase_month", columns="item_name",
values="item_price", aggfunc="sum", fill_value=0)
byPrice
# 월별, 고객 이름별 구입 수 집계
byCustomer = import_data.pivot_table(index="purchase_month", columns="고객이름",
aggfunc="size", fill_value=0)
byCustomer
# 월별, 지역별 판매 수 집계
byRegion = import_data.pivot_table(index="purchase_month", columns="지역",
aggfunc="size", fill_value=0)
byRegion
'Python > 데이터분석 공부' 카테고리의 다른 글
| [Python] 05장_회원 탈퇴를 예측하는 테크닉 (0) | 2022.03.18 |
|---|---|
| [Python] 04장_고객의 행동을 예측하는 테크닉 (425) | 2022.03.17 |
| [Python] 03장 _ 고객의 전체 모습을 파악하는 테크닉 (0) | 2022.02.16 |
| [Python] 01장 _ 웹에서 주문 수를 분석하는 테크닉 (391) | 2022.02.14 |