파이썬 데이터 분석 실무 테크닉 100
01장 _ 웹에서 주문 수를 분석하는 테크닉 [ 데이터 가공 ]
1. 데이터 불러오기
import pandas as pd
customer_master = pd.read_csv("C:/data/customer_master.csv")
customer_master.head()
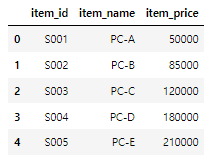
item_master = pd.read_csv("C:/data/item_master.csv")
item_master.head()
transaction_1 = pd.read_csv("C:/data/transaction_1.csv")
transaction_2 = pd.read_csv("C:/data/transaction_2.csv")
transaction_detail_1 = pd.read_csv("C:/data/transaction_detail_1.csv")
transaction_detail_2 = pd.read_csv("C:/data/transaction_detail_2.csv")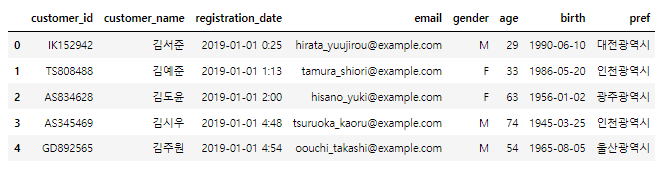
2. 데이터를 세로 방향으로 결합(union)하기
transaction_1, transaction_2는 같은 열에 대한 데이터 이므로 세로 결합
# 세로 방향 결합
transaction = pd.concat([transaction_1, transaction_2], ignore_index = True)
print(transaction_1.shape)
print(transaction_2.shape)
print(transaction.shape)
행열 개수를 확인해봤을 때 잘 결합된 것을 확인할 수 있다.
마찬가지로 transaction_detail_1, transaction_detail_2도 세로 결합 해주자
transaction_detail = pd.concat([transaction_detail_1, transaction_detail_2], ignore_index = True)
print(transaction_detail_1.shape)
print(transaction_detail_2.shape)
print(transaction_detail.shape)
행열 개수를 확인해봤을 때 잘 결합된 것을 확인할 수 있다.
transaction.head()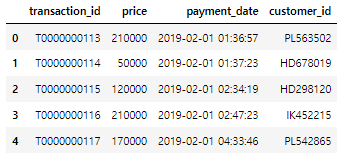
transaction_detail.head()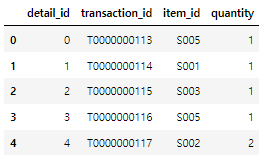
3. master 데이터를 결합(join)하기
join_data에 customer_master와 item_master 데이터를 결합해보자
공통된 컬럼은 각각 customer_id와 item_id이다.
join_data = pd.merge(join_data, customer_master, on = "customer_id", how = "left")
join_data = pd.merge(join_data, item_master, on = "item_id", how = "left")
join_data.head()
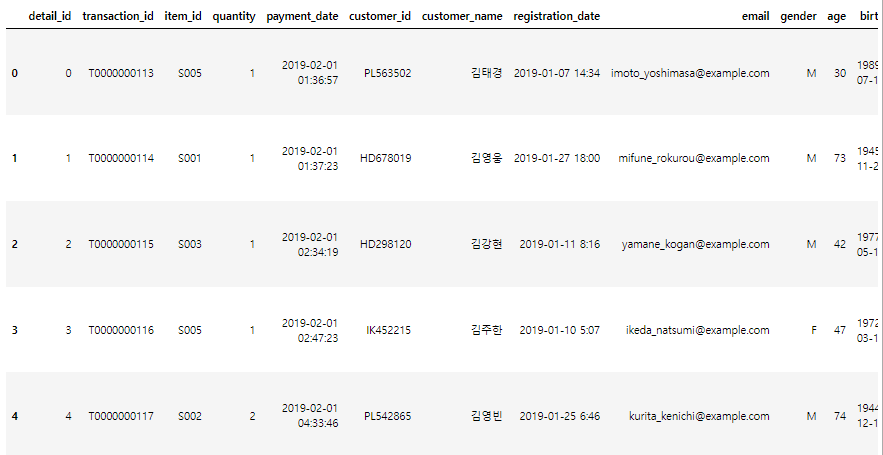
4. 필요한 데이터 칼럼 만들기
앞에서 제외했던 price 칼럼을 다시 만들어주자
매출은 quantity * item_price로 계산할 수 있다.
join_data["price"] = join_data["quantity"] * join_data["item_price"]
join_data[["quantity", "item_price", "price"]].head()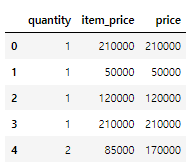
join_data["price"].sum() # 971135000
transaction["price"].sum() # 971135000원래 데이터의 price 합계와 비교해봤을때 잘 계산된 것을 확인할 수 있다.
5. 각종 통계량 파악하기
1. 결측치의 개수 확인하기
join_data.isnull().sum()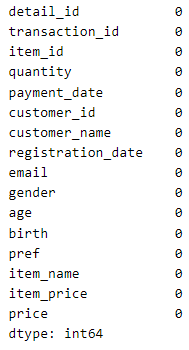
2. 각종 통계량 출력하기
join_data.describe()
3. 데이터의 기간 확인하기
# 데이터의 기간 파악
print(join_data["payment_date"].min()) # 2019-02-01 01:36:57
print(join_data["payment_date"].max()) # 2019-07-31 23:41:38
6. 월별로 데이터 집계하기
join_data.dtypespayment_data는 object형임을 확인했다.
이를 datetime형으로 바꾸고 새로운 칼럼을 생성하자
# payment_data를 datetime형으로 바꾸기
join_data["payment_date"] = pd.to_datetime(join_data["payment_date"])
join_data["payment_month"] = join_data["payment_date"].dt.strftime("%Y%m")
join_data[["payment_date", "payment_month"]].head()
# 월별 매출 집계
join_data.groupby("payment_month").sum()["price"]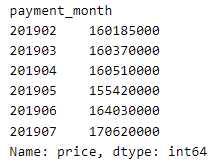
매출이 가장 높은 달은 7월, 가장 낮은 달은 5월임을 확인할 수 있다.
월별, 상품별로 어떤 제품이 잘 팔리는지 확인해보자
7. 월별, 상품별로 데이터 집계하기
join_data.groupby(["payment_month", "item_name"]).sum()[["price", "quantity"]]
# 위와 같은 결과를 피봇테이블로 집계해보기
pd.pivot_table(join_data, index = 'item_name', columns = 'payment_month',
values = ['price', 'quantity'], aggfunc = 'sum')
매출의 합계는 PC-E가 가장 높고, 수량의 합계는 값이 싼 PC-A가 가장 높은 것을 확인할 수 있다.
8. 상품별 매출 추이를 시각화 해보기
graph_data = pd.pivot_table(join_data, index = 'payment_month', columns = 'item_name',
values = 'price', aggfunc = 'sum')
graph_data.head()상품별 매출 추이를 시각화하기 위해 index는 payment_month, columns는 item_name으로 지정
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(list(graph_data.index), graph_data["PC-A"], label = 'PC-A')
plt.plot(list(graph_data.index), graph_data["PC-B"], label = 'PC-B')
plt.plot(list(graph_data.index), graph_data["PC-C"], label = 'PC-C')
plt.plot(list(graph_data.index), graph_data["PC-D"], label = 'PC-D')
plt.plot(list(graph_data.index), graph_data["PC-E"], label = 'PC-E')
plt.legend()
위에서 확인한 것과 같이 PC-E의 매출이 가장 높은 것을 확인할 수 있다.
※ 결론 : PC-E의 매출이 다른 상품에 비해 압도적으로 높다.
'Python > 데이터분석 공부' 카테고리의 다른 글
| [Python] 05장_회원 탈퇴를 예측하는 테크닉 (0) | 2022.03.18 |
|---|---|
| [Python] 04장_고객의 행동을 예측하는 테크닉 (425) | 2022.03.17 |
| [Python] 03장 _ 고객의 전체 모습을 파악하는 테크닉 (0) | 2022.02.16 |
| [Python] 02장 _ 대리점 데이터를 가공하는 테크닉 (401) | 2022.02.14 |