Breast Cancer Wisconsin Diagnostic
K-NN알고리즘으로 유방암 여부 진단
Breast Cancer Wisconsin (Diagnostic) Data Set
Predict whether the cancer is benign or malignant
www.kaggle.com
radius (mean of distances from center to points on the perimeter)
texture (standard deviation of gray-scale values)
smoothness (local variation in radius lengths)
compactness (perimeter^2 / area - 1.0)
concavity (severity of concave portions of the contour)
concave points (number of concave portions of the contour)
symmetry
fractal dimension ("coastline approximation" - 1)
Diagnosis (M = malignant, B = benign)
1. 데이터 준비 및 정규화
> wbcd = read.csv("C:/R/wisc_bc_data.csv", header=TRUE)
> wbcd = wbcd[-1] # id 열 삭제
> #str(wbcd)
> attach(wbcd)
> table(diagnosis)
diagnosis
B M
357 212
>
> # factor로 변환
> diagnosis = factor(diagnosis, levels=c("B", "M"),
+ labels=c("Benign", "Malignant"))
>
> # 비율 확인
> round(prop.table(table(diagnosis))*100, digits=1)
diagnosis
Benign Malignant
62.7 37.3
> summary(wbcd[c("radius_mean", "area_mean", "smoothness_mean")])
radius_mean area_mean smoothness_mean
Min. : 6.981 Min. : 143.5 Min. :0.05263
1st Qu.:11.700 1st Qu.: 420.3 1st Qu.:0.08637
Median :13.370 Median : 551.1 Median :0.09587
Mean :14.127 Mean : 654.9 Mean :0.09636
3rd Qu.:15.780 3rd Qu.: 782.7 3rd Qu.:0.10530
Max. :28.110 Max. :2501.0 Max. :0.16340- diagnosis 변수를 가변수로 만들어주었다.
- Benign과 Malignant의 비율은 62.6%, 37.3%이다.
K-NN의 거리 계산은 측정 범위에 크게 의존한다.
'radius_mean', 'area_mean', 'smoothness_mean'의 범위를 봤을 때 큰 차이가 나기 때문에 정규화를 해주어야 한다.
데이터 정규화 함수 normalize를 생성하여 적용해주었다.
> # 데이터 정규화
> normalize = function(x) {return ((x-min(x))/(max(x)-min(x)))}
> wbcd_n = as.data.frame(lapply(wbcd[2:31], normalize))
>
> summary(wbcd_n$radius_mean)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.0000 0.2233 0.3024 0.3382 0.4164 1.0000
> summary(wbcd_n$area_mean)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.0000 0.1174 0.1729 0.2169 0.2711 1.0000
> summary(wbcd_n$smoothness_mean)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.0000 0.3046 0.3904 0.3948 0.4755 1.0000- 위의 summary와 비교하면 0~1 사이로 잘 변환된 것을 알 수 있다.
다음으로, 훈련 데이터와 테스트 데이터를 9:1의 비율로 생성하였다.
> # 훈련, 테스트 데이터 생성
> 569*0.9 #512
> wbcd_train = wbcd_n[1:512,]
> wbcd_test = wbcd_n[513:569,]
> wbcd_train_labels = wbcd[1:512, 1] # 팩터
> wbcd_test_labels = wbcd[513:569, 1]
2. 모델 훈련
class 패키지의 knn() 함수를 사용하여 모델을 훈련한 후 성능을 평가했다.
> # 모델 훈련
> # install.packages("class")
> library(class)
> wbcd_test_pred = knn(train=wbcd_train, test=wbcd_test,
+ cl=wbcd_train_labels, k=23)
>
>
> # 모델 성능 평가
> # install.packages("gmodels")
> library(gmodels)
> CrossTable(x=wbcd_test_labels, wbcd_test_pred,
+ prop.chisq=F, prop.c=F, prop.r=F,
+ dnn = c('actual default', 'predicted default'))
(43+13)/57*100 # 98.24561
- k의 개수는 약 sqrt(512)인 23으로 지정하였다.
- 모델의 정확도는 약 98%로 높은 성능을 보인다.
3. 모델 성능 높이기
① k에 다른 값을 적용하여 분류해보기
# k=1
wbcd_test_pred = knn(train=wbcd_train, test=wbcd_test,
cl=wbcd_train_labels, k=1)
CrossTable(x=wbcd_test_labels, wbcd_test_pred,
prop.chisq=F, prop.c=F, prop.r=F,
dnn = c('actual default', 'predicted default'))
(40+13)/57*100 # 정확도 92.98%
# k=5
wbcd_test_pred = knn(train=wbcd_train, test=wbcd_test,
cl=wbcd_train_labels, k=5)
CrossTable(x=wbcd_test_labels, wbcd_test_pred,
prop.chisq=F, prop.c=F, prop.r=F,
dnn = c('actual default', 'predicted default'))
(42+13)/57*100 # 정확도 96.5%
# k=10
wbcd_test_pred = knn(train=wbcd_train, test=wbcd_test,
cl=wbcd_train_labels, k=10)
CrossTable(x=wbcd_test_labels, wbcd_test_pred,
prop.chisq=F, prop.c=F, prop.r=F,
dnn = c('actual default', 'predicted default'))
(41+14)/57*100 # 정확도 96.5%
# k=30
wbcd_test_pred = knn(train=wbcd_train, test=wbcd_test,
cl=wbcd_train_labels, k=30)
CrossTable(x=wbcd_test_labels, wbcd_test_pred,
prop.chisq=F, prop.c=F, prop.r=F,
dnn = c('actual default', 'predicted default'))
(43+13)/57*100 # 정확도 98.25%
② 정규화 대신 z-점수 표준화 사용
# z-점수 표준화
> wbcd_z = as.data.frame(scale(wbcd[-1]))
> summary(wbcd_z$radius_mean)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-2.0279 -0.6888 -0.2149 0.0000 0.4690 3.9678
> summary(wbcd_z$area_mean)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-1.4532 -0.6666 -0.2949 0.0000 0.3632 5.2459
> summary(wbcd_z$smoothness_mean)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-3.10935 -0.71034 -0.03486 0.00000 0.63564 4.76672
> wbcd_train = wbcd_z[1:512, ]
> wbcd_test = wbcd_z[513:569, ]
> wbcd_train_labels = wbcd[1:512, 1]
> wbcd_test_labels = wbcd[513:569, 1]
>
> wbcd_test_pred = knn(train = wbcd_train, test = wbcd_test,
+ cl = wbcd_train_labels, k=23)
> CrossTable(x = wbcd_test_labels, y = wbcd_test_pred,
+ prop.chisq=F, prop.c=F, prop.r=F,
+ dnn = c('actual default', 'predicted default'))
(43+13)/57*100 # 정확도 98.25%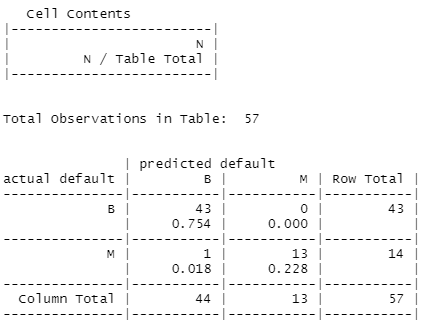
기존 모델의 정확도가 높았기 때문에 이 두 가지의 방법으로 모델의 성능이 개선되진 않았지만,
다른 케이스에 적용해보면 모델의 성능이 개선되는 것을 확인할 수 있을 것 같다!
'R > ML & DL 공부' 카테고리의 다른 글
| [R] 와인 등급 예측 - 회귀트리, 모델트리 (0) | 2022.04.22 |
|---|---|
| [R] 의료비 예측 - 선형 회귀 (0) | 2022.04.22 |
| [R] 휴대폰 스팸 분류 - Naive bayes (0) | 2022.04.20 |
| [R] 독버섯 분류 - 분류 규칙 (OneR, Ripper) (0) | 2022.04.19 |
| [R] 은행 대출 채무 여부 분류 - 의사결정트리 (0) | 2022.04.15 |