혼자 공부하는 머신러닝+딥러닝 책을 바탕으로 공부한 내용입니다.
CH7 딥러닝 시작 ①
인공 신경망 모델로 성능 향상
딥러닝과 인공 신경망 알고리즘을 이해하고 텐서플로를 사용해 간단한 인공 신경망 모델 만들어보기
▶ 패션 MNIST
텐서플로의 케라스 패키지를 import하고 패션 MNIST 데이터를 다운로드하자
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = \
keras.datasets.fashion_mnist.load_data()- keras.datasets.fashion_mnist 모듈 아래 load_data()는 훈련 데이터와 테스트 데이터를 나누어 반환해준다.
이 데이터의 크기를 확인해보자
print(train_input.shape, train_target.shape)
print(test_input.shape, test_target.shape)
- 훈련 데이터는 28X28크기인 이미지 60,000개로 이루어져 있다.
- 테스트 세트는 10,000개의 이미지로 이루어져 있다.
훈련 데이터에서 10개의 샘플을 뽑아 그림으로 출력해보자
# 이미지로 확인
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1, 10, figsize=(10, 10))
for i in range(10):
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()
이 샘플들의 타깃값을 확인해보면 다음과 같다.
# 샘플들의 타깃값 확인
print([train_target[i] for i in range(10)])
- 마지막 2개의 샘플은 같은 레이블을 가지고 있다. (같은 종류의 신발)

패션 MNIST에 포함된 10개의 레이블의 의미는 위와 같다.
마지막으로 레이블 당 샘플 개수를 확인해보자
# 샘플당 개수 확인
import numpy as np
print(np.unique(train_target, return_counts=True))
- 각 레이블마다 6,000개의 샘플이 들어있는 것을 확인할 수 있다.
▶ 로지스틱 회귀로 패션 아이템 분류하기
확률적 경사 하강법
- 여러 특성 중 기울기가 가장 가파른 방향을 따라 이동
- SGDClassifier을 사용할 때 표준화 전처리된 데이터를 사용한다.
패션 MNIST의 각 픽셀은 0~255 사이의 정숫값을 가진다.
이 이미지를 255로 나누어 0~1 사이의 값으로 정규화해주자 (표준화는 아니지만 양수 값으로 이루어진 이미지를 전처리할 때 널리 사용하는 방법)
# 정규화
train_scaled = train_input / 255.0
# 1차원 배열로 만들기
train_scaled = train_scaled.reshape(-1, 28*28)
print(train_scaled.shape)
- SGDClassifier는 2차원 입력을 다루지 못하므로 각 샘플을 1차원 배열로 만들어줬다.
- 784개의 픽셀로 이루어진 60,000개의 샘플이 준비되었다.
4장에서 한 것처럼 SGDClassifier 클래스와 cross_validate 함수를 사용해 이 데이터에서 교차 검증으로 성능을 확인해보자
# SGDClassifier
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log', max_iter=5, random_state=42)
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1)
print(np.mean(scores['test_score']))
- 반복 횟수 max_iter을 5번으로 지정했다.
▶ 인공 신경망으로 모델 만들기
- 생물학적 뉴런에서 영감을 받아 만든 머신러닝 알고리즘
- 이미지, 음성, 텍스트 분야에서 뛰어난 성능을 발휘하면서 크게 주목받고 있다.
로지스틱 회귀에서 만든 훈련 데이터 train_scaled, train_target을 사용해 모델을 만들어보자
로지스틱 회귀에서는 교차 검증을 사용해 모델을 평가했지만, 인공신경망에서는 교차 검증을 잘 사용하지 않고 검증 세트를 별도로 덜어내 사용한다.
이유 ① 딥러닝 분야의 데이터셋은 충분히 크기 때문에 검증 점수가 안정적이다
이유 ② 교차 검증을 수행하기에는 훈련 시간이 너무 오래 걸린다.
import tensorflow as tf
from tensorflow import keras
# 훈련세트, 검증세트
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
# 크기 확인
print(train_scaled.shape, train_target.shape)
print(val_scaled.shape, val_target.shape)
- 훈련 세트에서 20%를 검증 세트로 덜어내었다.
- 60,000개 중 12,000개가 검증 세트로 분리되었다.
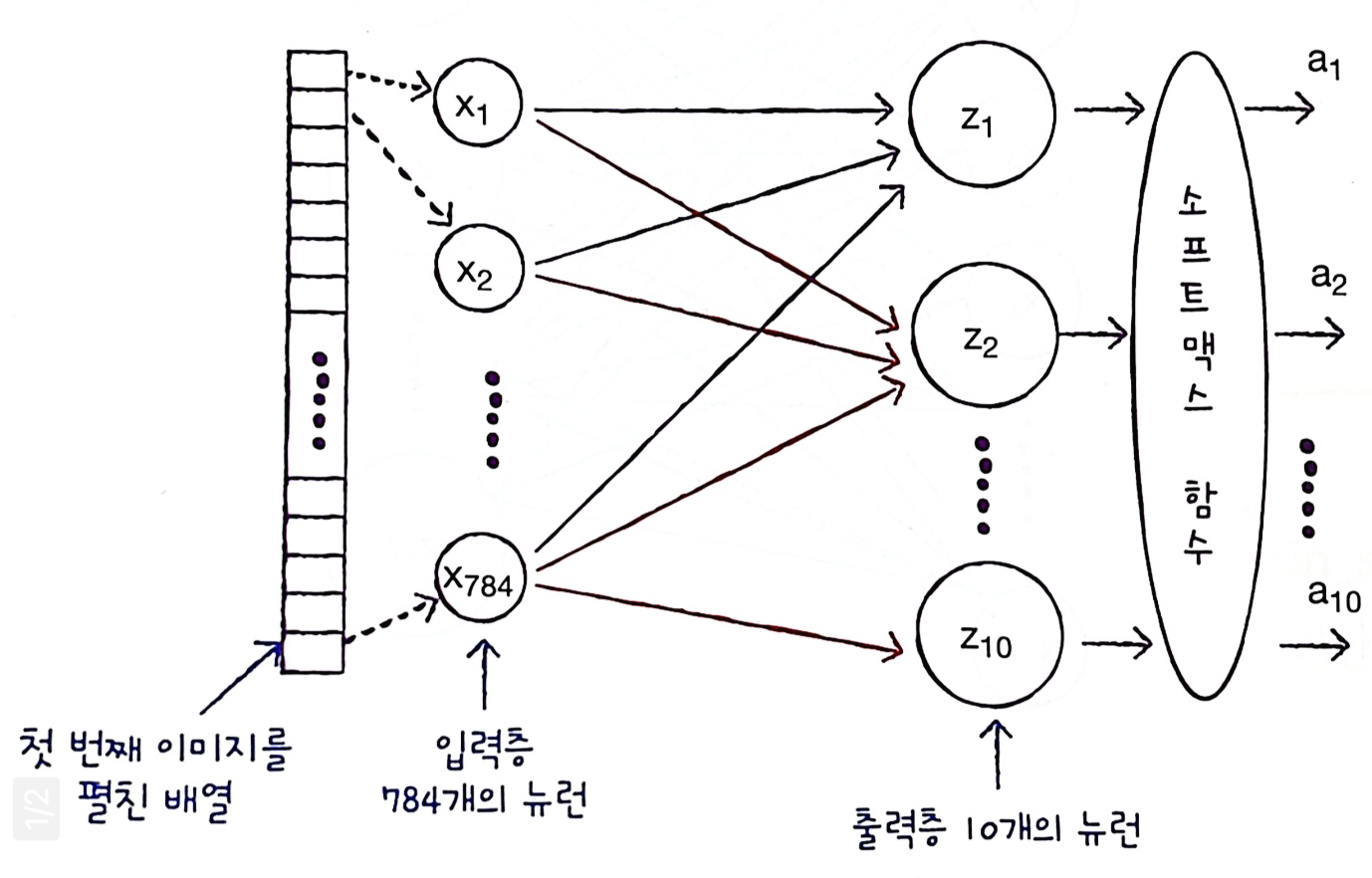
밀집층
- 가장 간단한 인공 신경망의 층
- 밀집층에서는 뉴런들이 모두 연결되어 있으므로 완전 연결 층이라고도 부른다.
- 특별히 출력층에 밀집층을 사용할 때는 분류하려는 클래스와 동일한 개수의 뉴런을 사용한다.
케라스의 Dense 클래스를 사용해 밀집층(출력층)을 만들어보자
# 밀집층 만들기
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))- 10개의 뉴런에서 출력되는 값을 확률로 바꾸기 위해 softmax 함수를 사용했다
- 만약, 이진 분류라면 시그모이드 함수를 사용
- input_shape는 입력값의 크기
- 10개의 뉴런이 각각 몇 개의 입력을 받는지 튜플로 지정 - 여기서는 784개의 픽셀값을 받는다
신경망 층을 만들었으므로 이 밀집층을 가진 신경망 모델을 만들어보자
# 신경망모델
model = keras.Sequential(dense)
▶ 인공 신경망으로 패션 아이템 분류하기
케라스 모델은 훈련하기 전 설정 단계가 있다.
이러한 설정을 model 객체의 compile() 메서드에서 수행하고 손실 함수의 종류를 꼭 지정해야 한다.
먼저 패션 MNIST 데이터의 타깃값을 확인해보면
# 타깃값 확인
print(train_target[:10])
원-핫 인코딩
- 정숫값을 배열에서 해당 정수 위치의 원소만 1이고 나머지는 모두 0으로 변환하는 것
- 이 변환이 필요한 이유는 다중 분류에서 출력층에서 만든 확률과 크로스 엔트로피 손실을 계산하기 위해서다.
- 텐서플로에서는 'sparse_categorical_entropy' 손실을 지정하면 이러한 변환을 수행하지 않아도 된다.
- 이는 정수로 된 타깃값을 사용해 크로스 엔트로피 손실을 계산하는 것
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')- 타깃값을 원-핫 인코딩으로 준비했다면 compile() 메서드에 손실 함수를 loss='categorical_crossentropy'로 지정
- 정확도를 함께 출력해주기 위해 metrics 매개변수에 accuracy를 지정해주었다.
이제 모델을 훈련해보자
# 모델 훈련
model.fit(train_scaled, train_target, epochs=5)
- 반복할 에포크 횟수를 epochs 매개변수로 지정하였다.
- 5번 반복에 정확도는 85%를 넘었다.
마지막으로 검증 세트에서 모델의 성능을 확인해보자
# 모델 성능 확인
model.evaluate(val_scaled, val_target)
- 케라스에서 모델의 성능을 평가하는 메서드는 evalutae() 메서드이다.
- 검증 세트의 점수는 85%인 것을 확인할 수 있다.
▶ 정리
- Dense
- 신경망에서 가장 기본 층인 밀집층을 만드는 클래스
- 첫번째 매개변수에는 뉴런의 개수 지정
- activation 매개변수에는 사용할 활성화 함수 지정 ( sigmoid, softmax 함수가 대표적, 지정하지 않으면 사용하지 않음)
- 케라스의 Sequential 클래스에 맨 처음 추가되는 층에는 input_shape 매개변수로 입력의 크기를 지정해야 함
- Sequential
- 케라스에서 신경망 모델을 만드는 클래스
- 클래스의 객체를 생성할 때 신경망 모델에 추가할 층을 지정할 수 있음
- 추가할 층이 1개 이상일 경우 파이썬 리스트로 전달
- compile()
- 모델 객체를 만든 후 훈련하기 전에 사용할 손실 함수와 측정 지표 등을 지정하는 메서드
- loss 메서드에 손실 함수 지정 - 이진 분류일 경우 'binary_crossentropy', 다중 분류일 경우 'categorical_crossentropy', 회귀 모델인 경우 'mean_square_error', 클래스 레이블이 정수인 경우 'sparse_categorical_crossentropy'
- metrics 매개변수에 훈련 과정에서 측정하고 싶은 지표 지정할 수 있음. 측정 지표가 1개 이상일 경우 리스트로 전달
'Python > ML & DL 공부' 카테고리의 다른 글
| [DL] 07-3 신경망 모델 훈련 (0) | 2022.03.27 |
|---|---|
| [DL] 07-2 심층 신경망 (0) | 2022.03.23 |
| [ML] 06-3 주성분 분석 (0) | 2022.03.12 |
| [ML] 06-2 k-평균 알고리즘 (0) | 2022.03.12 |
| [ML] 06-1 군집 알고리즘 (0) | 2022.03.12 |