혼자 공부하는 머신러닝+딥러닝 책을 바탕으로 공부한 내용입니다.
CH5 트리 알고리즘 ③
앙상블 학습을 통한 성능 향상
앙상블 학습이 무엇인지 이해하고 다양한 앙상블 학습 알고리즘을 실습을 통해 배워보자
앙상블 학습
- 더 좋은 예측 결과를 만들기 위해 여러 개의 모델을 훈련하는 머신러닝 알고리즘
- 정형 데이터를 다루는데 가장 뛰어난 성과를 내는 알고리즘
- 대부분 결정 트리를 기반으로 만들어져 있음
▶ 랜덤 포레스트
- 대표적인 결정 트리 기반의 앙상블 학습 방법
- 부트스트랩 샘플을 사용, 랜덤하게 일부 특성을 선택하여 트리를 만드는 것이 특징
- 랜덤하게 선택한 샘플과 특성을 사용하므로 과대적합을 막아주고, 안정적인 성능을 얻을 수 있음
- 사이킷런의 랜덤 포레스트는 기본적으로 100개의 결정 트리를 훈련
- RandomForestClassifier는 전체 특성 개수의 제곱근만큼의 특성을 선택
- RandomForestRegressor는 전체 특성을 사용
랜덤포레스트 분류 클래스를 화이트 와인 분류 문제에 적용해보자
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42)
cross_validate() 함수로 교차 검증을 수행하고, return_train_score 매개변수를 True로 지정하여
검증 점수, 훈련 세트에 대한 점수도 같이 반환해보자
# 교차 검증 수행 후 점수 확인
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target,
return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
이번에는 랜덤 포레스트 모델을 훈련한 후 특성 중요도를 출력해보자
# 모델 훈련 후 특성 중요도 출력
rf.fit(train_input, train_target)
print(rf.feature_importances_)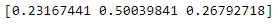
- 랜덤 포레스트는 특성의 일부를 랜덤하게 선택하여 결정 트리를 훈련
- 하나의 특성에 과도하게 집중하지 않고 많은 특성이 훈련에 기여할 기회를 얻음
- 과대적합을 줄이고 일반화 성능을 높이는데 도움
부트스트랩 샘플을 만들어 결정 트리를 훈련할 때, 부트스트랩 샘플에 포함되지 않고 남는 샘플(OOB 샘플)이 있다.
이 샘플을 이용해 부트스트랩 샘플로 훈련한 결정 트리를 평가할 수 있다. (검증 세트의 역할)
oob_score=True로 지정하고 모델을 훈련해 OOB 점수를 출력해보자
# OOB 점수 출력
rf = RandomForestClassifier(oob_score=True, n_jobs=-1, random_state=42)
rf.fit(train_input, train_target)
print(rf.oob_score_) #0.8934000384837406- OOB 점수를 사용하면 교차 검증을 대신할 수 있어서 훈련 세트에 더 많은 샘플을 사용할 수 있음
▶ 엑스트라 트리
- 랜덤포레스트와 비슷하게 결정 트리를 사용하여 앙상블 모델을 만들지만 부트스트랩 샘플을 사용하지 않음
- 많은 트리를 앙상블 하기 때문에 과대적합을 막고 검증 세트의 점수를 높이는 효과가 있음
- 기본적으로 100개의 결정 트리를 훈련함
이 모델의 교차 검증 점수를 확인해보자
# 엑스트라 트리 모델 교차 검증 점수 확인
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(et, train_input, train_target,
return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
- 엑스트라 트리는 랜덤 포레스트보다 더 많은 결정 트리를 훈련해야함
- 랜덤하게 노드를 분할하므로 계산 속도가 빠르다는 장점이 있음
엑스트라 트리도 랜덤 포레스트와 마찬가지로 특성 중요도를 제공한다
# 특성 중요도 확인
et.fit(train_input, train_target)
print(et.feature_importances_)
- 지난번 구했던 결정 트리보다 당도에 대한 의존성이 낮은 것을 확인할 수 있다.
▶ 그레이디언트 부스팅
- 랜덤 포레스트, 엑스트라 트리와 달리 결정 트리를 연속적으로 추가하여 손실 함수를 최소화하는 앙상블 방법
- 훈련 속도가 느리지만 더 좋은 성능을 기대할 수 있음
- 깊이가 3인 결정 트리 100개를 사용함 (과대적합에 강함)
- 경사 하강법 사용
- 분류에서는 로지스틱 손실 함수, 회귀에서는 평균 제곱 오차 함수 사용
그레이디언트 부스팅을 사용해 와인 데이터셋의 교차 검증 점수를 확인해보자
# 그레이디언트 부스팅 교차 검증 점수 확인
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=42)
scores = cross_validate(gb, train_input, train_target,
return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
- 그레이디언트 부스팅은 결정 트리의 개수를 늘려도 과대적합에 매우 강함
학습률을 증가시키고 트리의 개수를 늘려 성능을 더 향상시켜보자
# 학습율, 결정 트리 개수 늘리기
gb = GradientBoostingClassifier(n_estimators=500, learning_rate=0.2, random_state=42)
scores = cross_validate(gb, train_input, train_target,
return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))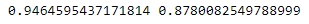
- 결정 트리 개수를 500개로 5배 늘렸고 학습률을 기본값인 0.1에서 0.2로 늘렸다
이번에는 특성 중요도를 확인해보자
# 특성 중요도 확인
gb.fit(train_input, train_target)
print(gb.feature_importances_)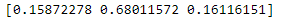
- 그레이디언트 부스팅은 랜덤 포레스트보다 당도(일부 특성)에 더 집중한다.
▶ 히스토그램 기반 그레이디언트 부스팅
- 그레이디언트 부스팅의 속도를 개선한 것
- 정형 데이터를 다루는 머신러닝 알고리즘 중에 가장 인기가 높은 알고리즘
- 입력 특성을 256개의 구간으로 나누므로 노드를 분할할 때 최적의 분할을 매우 빠르게 찾을 수 있음
- 256 구간 중 하나를 떼어 놓고 누락된 값을 위해 사용 (누락된 특성이 있어도 전처리 필요 X)
와인 데이터셋에 적용해보자
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
hgb = HistGradientBoostingClassifier(random_state=42)
scores = cross_validate(hgb, train_input, train_target,
return_train_score=True)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
- n_estimators 대신 부스팅 반복 횟수를 지정하는 max_iter를 사용한다.
- 과대적합을 잘 억제하며 그레이디언트 부스팅보다 조금 더 높은 성능을 보인다.
이번에는 permutation_importance() 함수를 사용해 train set과 test set의 특성 중요도를 확인해보자
# train set 특성 중요도 확인
from sklearn.inspection import permutation_importance
hgb.fit(train_input, train_target)
result = permutation_importance(hgb, train_input, train_target,
n_repeats=10, random_state=42, n_jobs=-1)
print(result.importances_mean)
# test set 특성 중요도 확인
result = permutation_importance(hgb, test_input, test_target,
n_repeats=10, random_state=42, n_jobs=-1)
print(result.importances_mean)
- n_repeats 매개변수로 랜덤하게 섞을 횟수를 10으로 지정하였다.
- permutation_importance()는 특성 중요도, 평균, 표준편차를 반환한다.
- 그레이디언트 부스팅과 비슷하게 조금 더 당도에 집중하고 있다는 것이 확인된다.
마지막으로 test set에서의 성능을 확인해보자
# 성능 확인
hgb.score(test_input, test_target) #0.8723076923076923- 앙상블 모델은 단일 결정 트리보다 좋은 결과를 얻을 수 있다.
▶ 정리
- 랜덤 포레스트 - 가장 대표적인 앙상블 학습 알고리즘
- 성능이 좋고 안정적
- 부트스트랩 샘플을 만들고 전체 특성 중 일부를 랜덤하게 선택하여 결정 트리를 만든다
- 엑스트라 트리
- 부트스트랩 샘플을 사용하지 않고 노드를 분할할 때 랜덤하게 분할한다
- 랜덤 포레스트보다 훈련 속도가 빠르지만 더 많은 트리가 필요하다
- 그레이디언트 부스팅
- 깊이가 얕은 트리를 연속적으로 추가하여 손실 함수를 최소화하는 앙상블 방법
- 성능이 뛰어나지만 병렬로 훈련할 수 없어 랜덤 포레스트나 엑스트라 트리보다 훈련 속도가 느리다
- 학습률 매개변수를 조정하여 모델의 복잡도를 제어할 수 있음
- 학습률매개변수가 크면 복잡하고 훈련 세트에 과대적합된 모델을 얻는다
- 히스토그램 기반 그레이디언트 부스팅 알고리즘
- 가장 뛰어난 앙상블 학습으로 평가받는 알고리즘
- 훈련 데이터를 256개의 구간으로 변환하여 사용하므로 노드 분할 속도가 매우 빠르다
'Python > ML & DL 공부' 카테고리의 다른 글
| [ML] 06-2 k-평균 알고리즘 (0) | 2022.03.12 |
|---|---|
| [ML] 06-1 군집 알고리즘 (0) | 2022.03.12 |
| [ML] 05-2 교차 검증과 그리드 서치 (0) | 2022.03.11 |
| [ML] 05-1 결정 트리 (0) | 2022.03.11 |
| [ML] 04-2 확률적 경사 하강법 (0) | 2022.03.10 |