Pima Indians Diabetes 예측하기
① EDA, 시각화 탐색
다음 데이터셋을 이용하였습니다.
https://www.kaggle.com/uciml/pima-indians-diabetes-database
Pima Indians Diabetes Database
Predict the onset of diabetes based on diagnostic measures
www.kaggle.com
Pregnancies : 임신 횟수
Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도
BloodPressure : 이완기 혈압(mm Hg)
SkinThickness : SkinThicknessTriceps 피부 주름 두께 (mm)
Insulin : 2시간 혈청 인슐린 (mu U / ml)
BMI : 체질량 지수 (체중kg /키(m)^2)
DiabetesPedigreeFunction : 당뇨병 혈통 기능
Age : 나이
Outcome : 768개 중에 268개의 결과 클래스 변수(0 또는 1)는 1이고 나머지는 0
▶ 준비과정
1. 필요한 라이브러리 가져오기
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
2. 데이터 로드 후 살펴보기
df = pd.read_csv("C:/data/diabetes.csv")
df.shape # (768, 9)
df.head()
# info로 데이터 타입, 결측치, 메모리 사용량 등의 정보 확인
df.info()
# 결측치 보기
df.isnull().sum()
# 수치데이터에 대한 요약 보기
df.describe()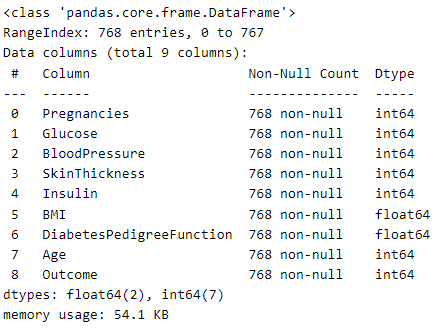

- Glucose, BloodPressure, SkinThickness, Insulin등의 최솟값이 0이다.
- 다음 컬럼들의 값은 0이 될 수 없으므로 이는 결측치라고 생각된다.
마지막 열 Outcome은 label값이므로 이를 제외하고 학습, 예측에 사용할 컬럼을 만들어주기
feature_columns = df.columns[:-1].tolist()
feature_columns
▶ EDA
1. 결측치 처리하기
결측치가 존재하는 컬럼을 슬라이싱을 통해 가져오기
cols = feature_columns[1:]
cols
0값을 결측치라 가정하고 cols에 해당되는 컬럼에 대해 결측치 여부를 구하여 df_null이라는 데이터프레임에 저장하기
df_null = df[cols].replace(0, np.nan)
df_null = df_null.isnull()
df_null.sum()
# 결측치의 개수를 구해 막대 그래프로 시각화
df_null.sum().plot.barh()
- Insulin 컬럼에 결측치가 많이 존재하는 것이 확인된다.
2. 상관 분석 해보기
정답값인 Outcome을 제외하고 feature로 사용할 컬럼들에 대해 0을 결측치로 만들어주었다.
df_matrix = df.iloc[:,:-2].replace(0, np.nan)
df_matrix["Outcome"] = df["Outcome"]
df_matrix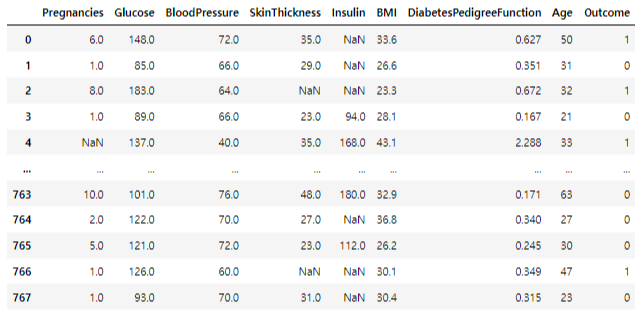
# 상관계수 구하기
df_corr = df_matrix.corr()
df_corr.style.background_gradient()
heatmap을 이용해서 시각화 할 수도 있다.
# 위에서 구한 상관계수를 heatmap으로 시각화
# annot쓰면 숫자도 보여짐
plt.figure(figsize=(15,8))
sns.heatmap(df_corr, annot=True, vmax=1, vmin=-1, cmap="coolwarm")
- Insulin과 Glucose, Age와 Pregnancies, BMI와 SkinThickness 등의 상관계수가 높은 것이 확인 된다.
3. 여러 방식으로 시각화해보기
정답값(Outcome)의 개수와 비율 살펴보기
# Outcome의 개수 보기
df["Outcome"].value_counts()
# Outcome 비율 보기
df["Outcome"].value_counts(normalize=True)
- 당뇨병 발병 비율이 약 35%임이 확인된다.
(1) Outcome과 Pregnancies가 어떤 관련이 있는지 시각화 해보기
df_po = df.groupby(["Pregnancies"])["Outcome"].agg(["mean", "count"]).reset_index()
df_po
# 임신횟수에 따른 당뇨병 발병 비율
df_po["mean"].plot.bar(rot=0)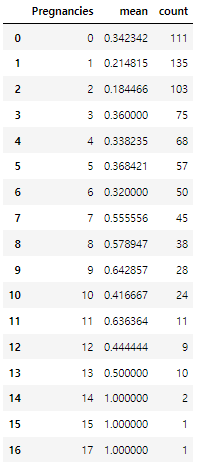

- 임신횟수가 증가할수록 당뇨병 발병 비율도 증가하는 것이 확인된다.
- 임신횟수가 많은 사람은 count가 적은 것이 확인된다.
(2) countplot으로 그려보기
# 임신횟수에 따른 당뇨병 발병 빈도수 비교
# hue는 색상 다르게 설정
sns.countplot(data=df, x="Pregnancies", hue="Outcome")
- 임신 횟수가 6번 이하일 때는 당뇨병이 발병하지 않을 확률이 더 높고, 7번 이상은 당뇨병 발병 확률이 더 높다.
(3) Distplot로 시각화 해보기
distplot은 주로 1개의 수치형 변수의 빈도수를 시각화할 때 사용한다.
당뇨병이 발병하지 않은 케이스를 df_0, 발병한 케이스를 df_1에 넣어주고 시각화하기
df_0 = df[df["Outcome"] == 0]
df_1 = df[df["Outcome"] == 1]
df_0.shape, df_1.shape # ((500, 10), (268, 10))# 임신횟수에 따른 당뇨병 발병 여부 시각화
sns.distplot(df_0["Pregnancies"])
sns.distplot(df_1["Pregnancies"])

- 임신횟수가 많아질수록 당뇨병 발병율이 높다고 볼 수 있다.
나이에 따른 당뇨병 발병 여부도 시각화 해보기
# 나이에 따른 당뇨병 발병 여부 시각화
sns.distplot(df_0["Age"], hist=False, rug=True, label=0)
sns.distplot(df_1["Age"], hist=False, rug=True, label=1)
- 30세 이전은 발병하지 않을 확률이 높고, 30세 이후는 발병이 더 많은 것 보여진다.
(4) 정답값(Outcome)과 BMI, Glucose, Insulin들과 어떤 관련이 있는지 시각화 해보기
# 당뇨병 발병에 따른 BMI 수치 비교
sns.barplot(data=df, x="Outcome", y="BMI")
# 당뇨병 발병에 따른 포도당(Glucose)수치 비교
sns.barplot(data=df, x="Outcome", y="Glucose")
# Insulin 수치가 0 이상인 관측치에 대해서 당뇨병 발병 비교
sns.barplot(data=df, x="Outcome", y="Insulin")


- 당뇨병 발병 여부에 따라 BMI, Glucose, Insulin이 약간씩 차이가 있는 것으로 보인다.
Subplot을 이용하여 한번에 여러 그래프를 그려보기
(5) Distplot로 시각화 해보기
# 컬럼의 수 만큼 for문을 만들어서 서브플롯으로 시각화
col_num = df.columns.shape
cols = df.columns[:-1].tolist()
fig, axes = plt.subplots(nrows=4, ncols=2, figsize=(15, 15))
for i, col_name in enumerate(cols[:-1]):
row = i // 2
col = i % 2
sns.distplot(df_0[col_name], ax=axes[row][col])
sns.distplot(df_1[col_name], ax=axes[row][col])
(6) Violinplot을 이용해 데이터의 분포를 시각화 해보기
- 가운데 흰색 점 - 중앙값
- 두꺼운 선 - 사분위의 범위
- 중앙의 얇은 선 - 신뢰구간
# violinplot으로 서브플롯 그려보기
fig, axes = plt.subplots(nrows=4, ncols=2, figsize=(15, 15))
for i, col_name in enumerate(cols[:-1]):
row = i // 2
col = i % 2
sns.violinplot(data=df, x="Outcome", y=col_name, ax=axes[row][col])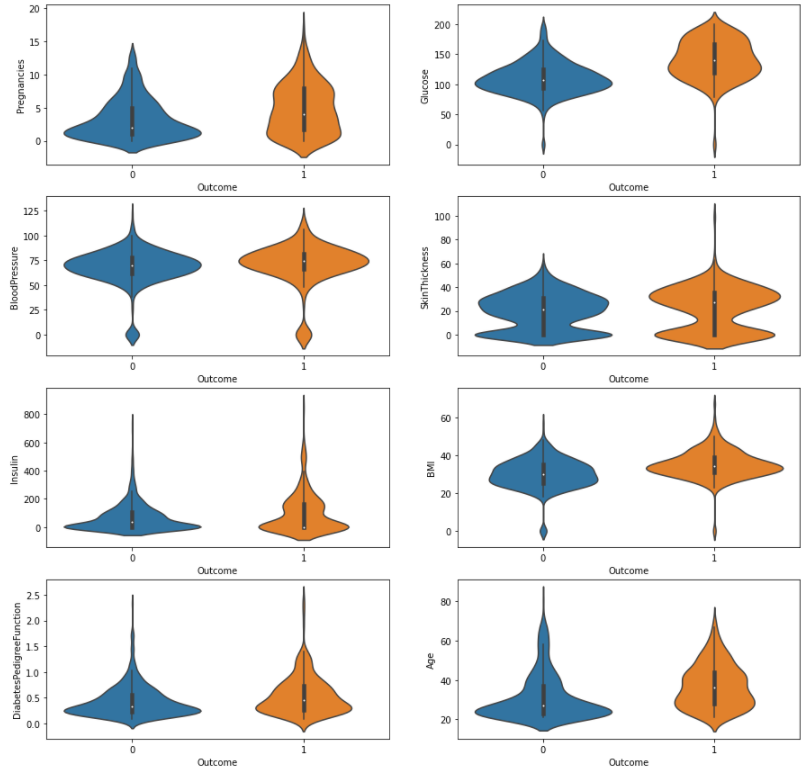
(7) Regplot와 lmplot으로 시각화하기
regplot은 scatter와 line을 함께 보여주는 시각화 방법이다.
regplot은 hue옵션이 없지만 lmplot은 hue 옵션이 있어 색상을 다르게 지정할 수 있다는 장점이 있다.
sns.regplot(data=df, x="Glucose", y="Insulin")
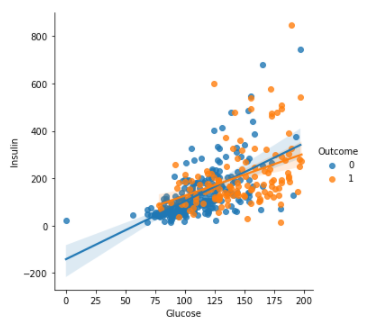
sns.lmplot(data=df, x="Glucose", y="Insulin", hue="Outcome")

인슐린이 0(결측치)인 값이 많으므로 인슐린 수치가 0 이상인 데이터에 대해서만 그려보기
# Insulun 수치가 0 이상인 데이터로만 그리기
sns.regplot(data=df[df["Insulin"]>0], x="Glucose", y="Insulin")
sns.lmplot(data=df[df["Insulin"]>0], x="Glucose", y="Insulin", hue="Outcome")
(8) pairplot으로 상관관계 나타내기
sns.pairplot(df)
(9) pairGrid로 상관관계 나타내기
pairplot과 유사하고, hue 옵션을 통해 색상을 표현할 수 있다.
# PairGrid를 통해 모든 변수에 대해 Outcome에 따른 scatterplot 그리기
g = sns.PairGrid(df, hue="Outcome")
g.map(plt.scatter)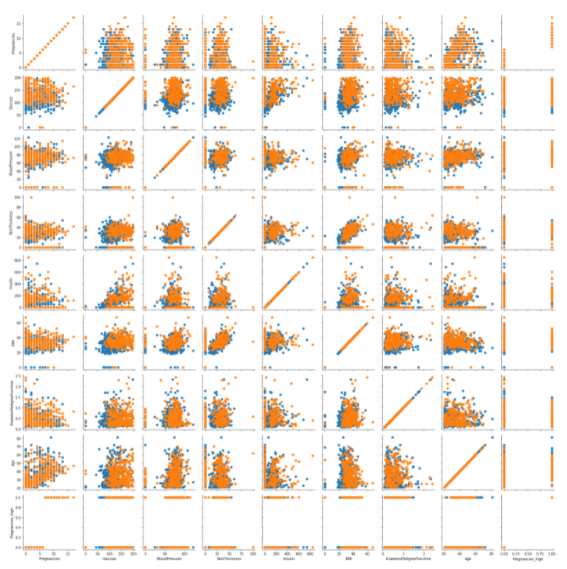
다음 수업을 바탕으로 실습하였습니다.
프로젝트로 배우는 데이터사이언스
부스트코스 무료 강의
www.boostcourse.org
'Python > 데이터분석 실습' 카테고리의 다른 글
| [Kaggle] 자전거 수요 예측 ① 데이터 확인 & EDA (0) | 2022.05.03 |
|---|---|
| [Kaggle ] Pima Indians Diabetes 예측 ② 데이터 전처리 후 모델 학습/예측 (0) | 2022.03.01 |
| [Python] 국가(대륙)별/상품군별 온라인쇼핑 해외직접판매액 데이터 분석 (0) | 2022.02.04 |
| [Python] 서울 종합병원 분포 데이터 분석 (0) | 2022.02.04 |
| [DACON_101] Lv.2 결측치 보간법과 랜덤포레스트로 따릉이 데이터 예측하기 (0) | 2022.02.02 |